Versal ACAP AI Engine для чайников
Введение в ACAP Versal TM
Versal TM Adaptive Compute Acceleration Platform (ACAP) - это последнее поколение устройств Xilinx, построенных на техпроцессе TSMC 7 нм FinFET. Они сочетают в себе скалярные вычислительные модули (процессорную систему (PS)), программируемую логику (PL) и интеллектуальные модули. Все эти части объединяются с помощью высокоскоростной сети на кристалле (NoC).

В этой статье основное внимание уделяется модулям (IP ядрам) искусственного интеллекта, которые являются частью интеллектуальных модулей.
Введение в модули Xilinx AI
Модули AI включены в ACAP Xilinx Versal семейства AI Core. Они организованы как двумерный массив модулей AI Engine, которые соединены вместе с интерфейсами памяти, а так же потоковым и каскадным интерфейсами . Этот массив может содержать до 400 элементов AI (например, на устройстве VC1902). Массив также включает AI Engine interface , расположенный в последней строке массива, что позволяет массиву взаимодействовать с остальной частью устройства (PS, PL и NoC).
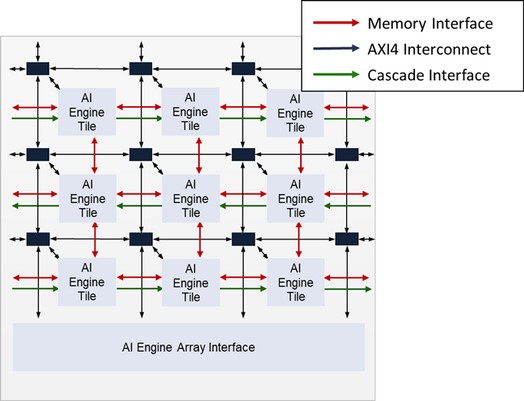
AI Engine Interface включает ,блоки связи с PL и NoC и модуль конфигурации. Интерфейс от PL к массиву AI Engine выполняется с использованием интерфейсов AXI4-Stream через модули интерфейса PL и NoC. Интерфейс от NoC к массиву AI Engine выполняется с использованием интерфейсов AXI4-MM (MM-Memory Mapped) через модули интерфейса NoC.
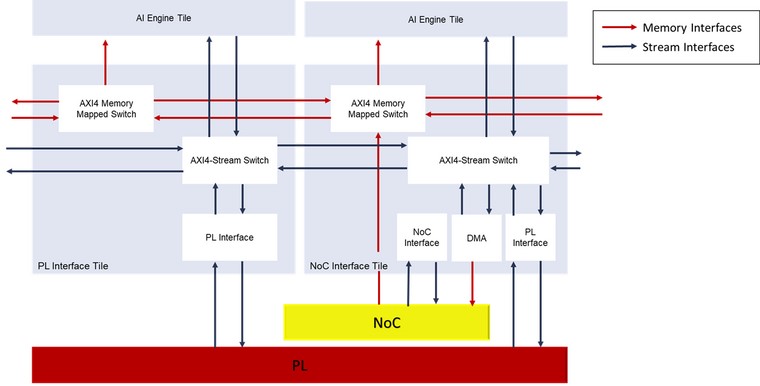
Интересно отметить, что прямой канал связи AXI4-MM доступен только от NoC к блокам AI Engine, но не в обратную сторону.
Примечание: Точное количество модулей интерфейса PL и NoC зависит от устройства и указан в документе Versal Architecture and Product Data Sheet: Overview (DS950).
Архитектура блока AI Engine
Рассмотрим теперь подробнее архитектуру одной ячейки матрицы AI Engine и внутреннюю структуру отдельного вычислительного модуля.
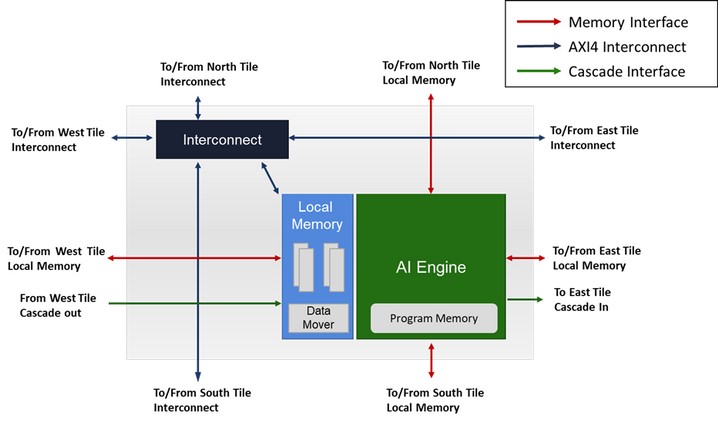
Каждая ячейка AI Engine включает в себя:
- Один модуль связи с каналами в/в AXI4-Stream и AXI4-ММ
- Один модуль памяти на 32 KB данных, разделенных на 8 банков, интерфейс памяти, модуль DMA и механизм блокировок.
- Один модуль AI Engine
Модуль AI Engine может иметь доступ максимум к 4 модулям памяти по четырем направлениям, составляющих непрерывное адресное пространство. Таким образом, отдельный блок AI может адресоваться не только к своей памяти, но и к памяти трех своих соседей (если, конечно, не находится на краю массива).
Архитектура модуля AI Engine
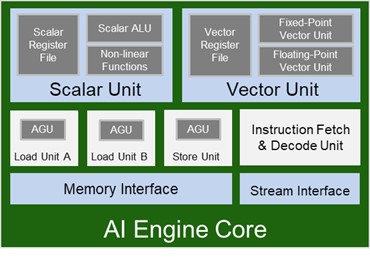
Модуль AI Engine – глубоко оптимизированный процессор, состоящий из следующих частей:
- 32хбитный скалярный процессор RISC (или Скалярный модуль)
- 512и-битный SIMD модуль векторных вычислений, выполняющий целочисленные/с фиксированной точкой и модуль векторных вычислений с плавающей точкой одинарной точности. (SPFP)
- Три блока генерации адреса
- Блок декодирования и обработки очень длинных команд (Very-long instruction word, VLIW) Three data memory ports (Two load ports and one store port)
- Потоковый интерфейс с двумя входными и двумя выходными потоками В/В.
Программирование массива AI Engine
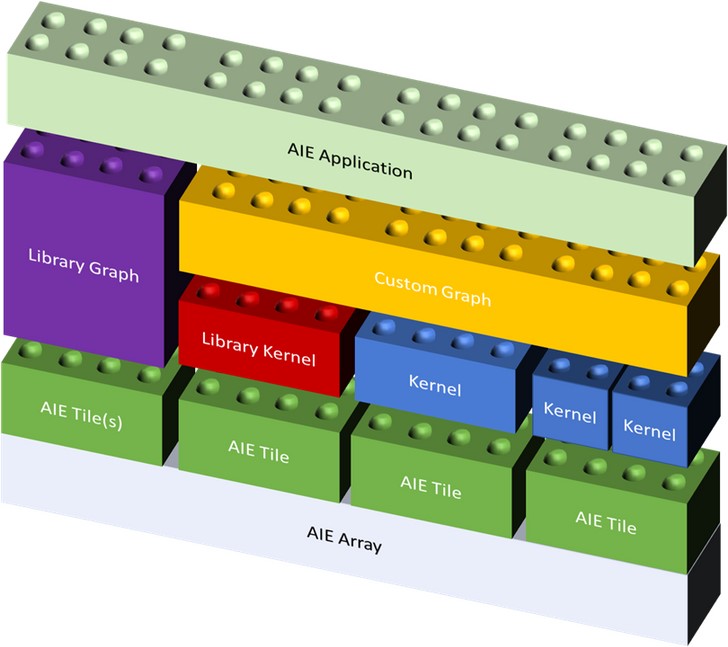
AI Engine скомпонованы в массивы, содержащие от 10 до 100 отдельных модулей. Создание единой программы параллельных вычислений для них с было бы чрезвычайно утомительной, почти невыполнимой задачей. Поэтому программирование массива AI Engine производится по модели Kahn Process Networks, в которой автономные вычислительные процессы соединены друг с другом с помощью создаваемых сетевых процессов. (см. https://www.researchgate.net/publication/265767109_Kahn_networks_at_the_dawn_of_functional_programming)
В AI Engine framework, ребра графа представляют собой буфера и потоки, а вычислительные процессы называются kernels (ядра). Кернелы инстантиируются и связываются друг с другом, а так же с остальной аппаратурой (NoC, PL) с помощью графов.
Процесс программирования происходит в две стадии:
Программирование отдельных кернелов:
Кернел описывает некоторый вычислительный процесс. Каждый кернел выполняется на одной ячейке AI Engine, однако одна ячейка AI Engine может обрабатывать несколько кернелей в режиме разделения времени.
Для программирования AI Engine используется код на C/C++. Большая часть кода выполняется на скалярном процессоре. Для достижения максимальной производительности кернела, требуется использовать векторный процессор, используя специальные функции называемые интринсиками (intrinsics). Эти функции предназначены для векторного процессора AI Engine и обеспечивают достижение высокой производительности обработки.
Xilinx предоставляет программистам готовые библиотечные ядра, которые они могут использовать в своих графах.
Программирование графа:
Xilinx предоставляет собственный С++ фреймворк для создания графов из кернелей. Этот фреймворк включает в себя описание узлов и связей графов. Узлы могут располагаться как в массиве AI Engine так и в программируемой логике (HLS kernel). Для обеспечения полного контроля над размещением кернелей, используется набор методов, управляющих процессом размещения кернелов, а так же буферов, системной памяти и т.д). Граф описывает инстанциацию кернелей и их соединения посредством буферов и потоков. Он так же описывает передачу данных в AI Engine Array и из него в другие части ACAP (PL, DDR, … ).
Xilinx так же предоставляет библиотеку готовых графов различного применения, которые могут встраиваться в приложения пользователей.
Во время выполнения и моделирования приложение AI Engine управляется со стороны PS.
Также Xilinx предоставляет компоненты времени выполнения, в зависимости от применяемой пользователем ОС:
• Библиотеку Xilinx Run Time (XRT) и приложение OpenCL для Linux-систем
• Драйверы для приложений, работающих на “голом железе”
Оригинал статьи.
Авторы: Оливье Тремуа, технический маркетинг AI Engine Tools, и Флоран Вербрук, инженер технической поддержки Xilinx по применению продуктов
Перевод: ГК Макро Групп - официальным дистрибьютором ПЛИС Xilinx.
Редактор: Владимир Вилукин - инженер по применению Xilinx.
Любые вопросы по продукции Xilinx задавайте по по телефону 8 (800) 333-06-05.
Дополнительные ссылки:
Информация по ACAP Versal: http://www.xilinx.com/versal
Информация по Versal AI Engine:
- Versal ACAP AI Engine Architecture Manual - AM009
- Статья в блоге Xilinx Unveiled the Secret Sauce of the Ultimate AI Inference Compute at XDF ‒ Versal AI Engine Array
- AI Engine white Paper: WP506 - Xilinx AI Engines and Their Applications
Обращаем Ваше внимание, что Versal ACAP AI Engine все еще находится в раннем доступе до выпуска 2020.2. До этого никакой информации, кроме той, которая содержится в документе AM009, предоставлено не будет. Инструменты программирования AI Engine также находятся в раннем доступе. Они так же станут доступны в открытом доступе начиная с версии 2020.2.
